SpecMesh - Provisioning Kafka resources using the AsyncAPI Spec, May 2023
– Neil Avery
In this blog, I will discuss how SpecMesh utilizes the AsyncAPI spec to provision Kafka resources and how it extends some of AsyncAPI spec functionality through its textual structuring introduced via regular text patterns. The AsyncApi spec is normally used for documentation purposes - we regularly see it being used for capturing existing deployments - SpecMesh inverts this to a position where it is used as the source of truth in a GitOps workflow and the provisioning of Kafka resources and governance (it can also export a spec).
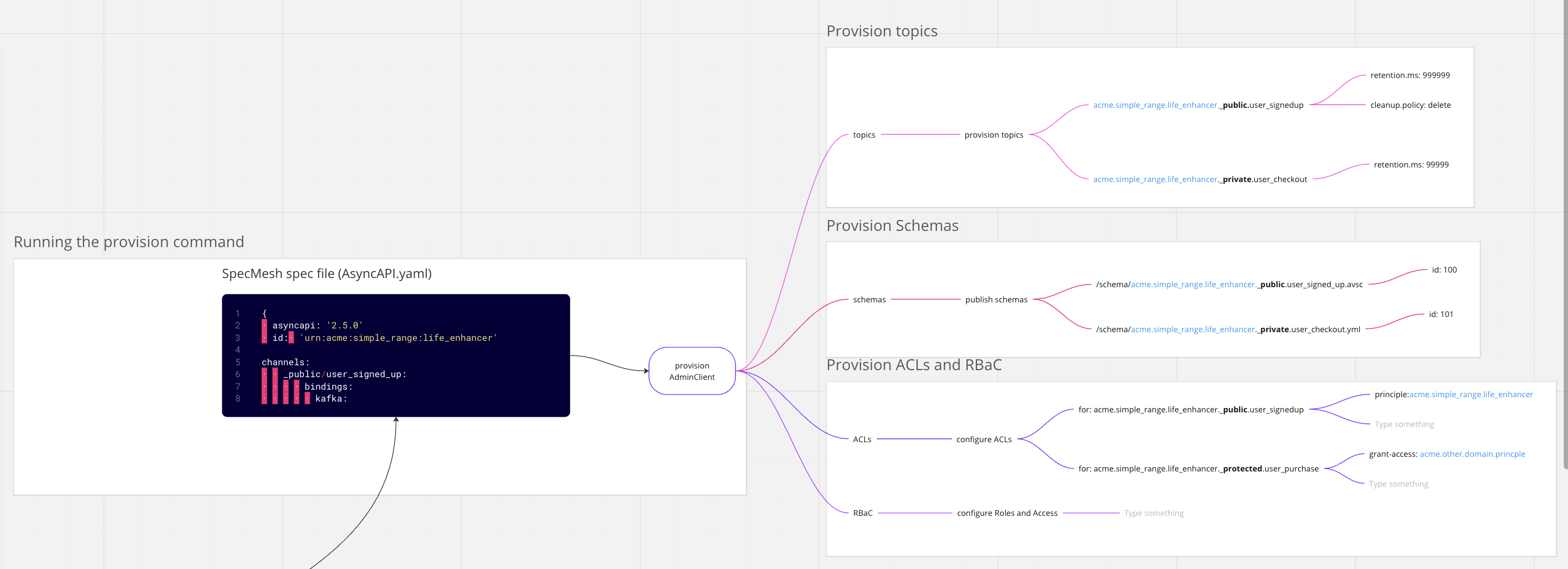
In the image below is a snippet of a spec. One of the first elements to note is the ID field in the AsyncAPI spec, which is used recurrently for various purposes.
asyncapi: '2.5.0'
id: 'urn:acme:simple_range:life_enhancer'
channels:
_public/user_signed_up:
bindings:
kafka:
partitions: 3
replicas: 1
configs:
retention.ms: 999000
publish:
summary: Inform about signup
operationId: onSignup
message:
payload:
$ref: "/schema/acme.simple_range.life_enhancer._public.user_signed_up.avsc"
The primary purpose of this ID field extends beyond merely understanding the name or identification of the data product. It also aims to structurally map it within the organisation for domain ownership (and functionality). For instance, in our case, the data product includes “ACME, Simple Range, and Life Enhancer”. In this fictitious structure, it’s broken down as company.product-group.product. With DDD (Domain-Driven Design), we aim to decompose things into aggregates, which are groups of related functionality (a cluster of services ideally from the same aggregate level repository, thus supporting black box testing) rather than relying on organizational groupings.
The ID is prefixed to individual channels or topics, as they are known in Kafka. Each of the channels owned by the Life Enhancer product is prefixed with either a _public or _private keyword. Additionally, the _protected keyword is also employed for self-governance purposes where restricting access to specific ‘domain ids’ is required.
Within each section, we have a Kafka configuration section and the schema related to it. The schema captures the data format of the event set to be published. Hence, the ID serves multiple purposes, with the key purpose being the principal. This allows for clear ownership when any resource is provisioned on behalf of this data product. Topics are prefixed with the principal, schemas are published into the schema registry prefixed with a schema principal, and ACLs also use the prefix. ACLs are governed or controlled by the keywords public, private, or protected.
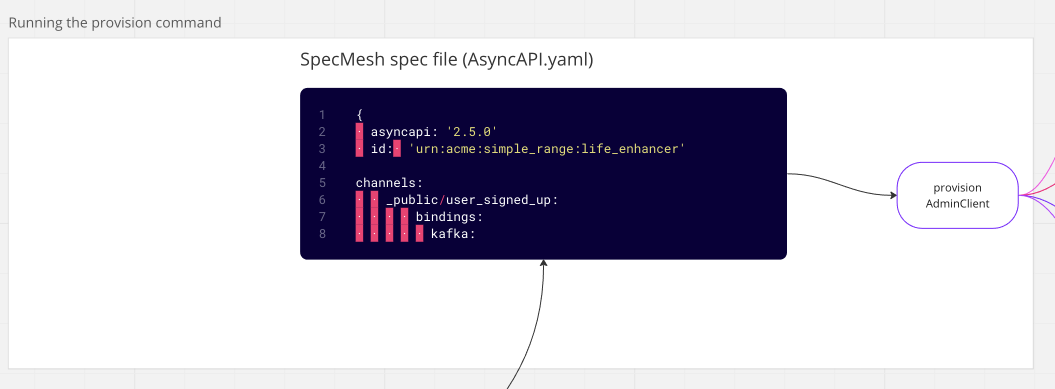
Suppose our developer has designed the data model for their data product. The next step is to provision an environment (local machine, or cluster). The provision command, part of the SpecMesh CLI, utilizes the Kafka admin client. This admin client can be used against any Kafka infrastructure, such as MSK, Open Source Apache Kafka, Confluent Cloud, Red Panda, or others. The provision command, executed from the command line, through Docker, or a GitHub workflow as part of a pull request, then provisions the topics.
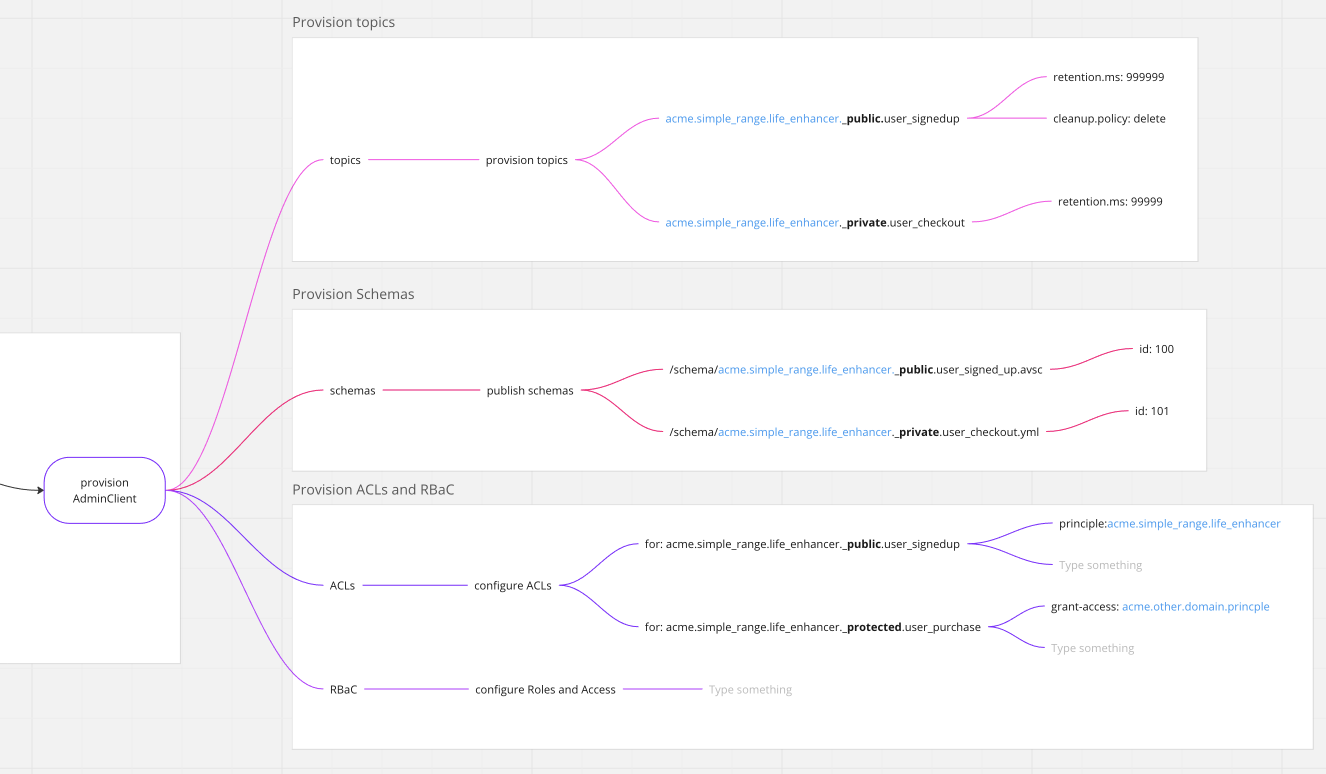
You will see the principal ID, ACME Simple Range Live Enhancer, prefixing each of the topics. The entire thing is concatenated together, and the configuration of retention and cleanup policies is specified. Schemas are then published into the Schema Registry, where ownership is clearly identified by the principal or the data product ID. ACLs, however, are slightly different. Controlled by public, private, and protected, the application owner or the data product owner in the case of protected can self-govern and use tags within the spec to grant access to other domains. When SpecMesh provisions this data product, it configures those ACLs accordingly (_private, _public, protected). Role-based Access (RBAC) is currently being developed and will be available soon.
Key points:
- AsyncAPI extension:
idis used to identify the data-product using domain driven thinking, it also represents the security principal (secrets etc), as well as the Aggregate in the context of an business’s function (not an org map). This is one of the pillars of DataMesh - Ownership of ‘data product’ resources is established by prefixing the
idto all resources - AsyncAPI extension: Prefixing channels (topics) using
_private,_public, and_protectedprovides sharing controls and suppress the need for understanding ACL configuration. - AsyncAPI extension:
_protectedtopics provide a means of fine-grained self-governance using thetag: grant-accesspattern. This is one of the pillars of DataMesh
..
View the YouTube recording of this post
