SpecMesh OS - Journey to the event-driven enterprise with Apache Kafka - Part 2 of 2, June 2023

– Neil Avery (Ex-Confluent)
Reviewed by Andy Coates (Ex-Confluent), Stanislav Kozlovski (Confluent)
Part 2: Architecting the Future: Embracing Event-Driven Architecture in the Enterprise
In recent years, we’ve observed several significant trends that prompt us to reassess our beliefs about constructing large-scale enterprise systems. By ’large scale’, I’m actually referring to a vast number of interconnected applications.
In part one, I discussed our approach to understanding events and began to touch on Domain orientation. In this part, I am going to address trends and considerations for the wider enterprise. Each one of these brings with it a plethora of beliefs and fundamentals – all of which are essential to building a successful solution for the enterprise. Unfortunately, there isn’t a single product capable of perfectly fitting the unique characteristics of an organisation’s DNA. However, as we’ll see later, SpecMesh OS significantly accelerates the implementation of a clean solution, providing effective guardrails and promoting best practices.
These trends can be categorized into:
- Event-driven architecture at the enterprise level
- Domain Driven Design, particularly focusing on Aggregates and Bounded Contexts,
- Data Mesh, characterised by its four pillars, which also incorporate elements from the above two points. Pillars: Governance, Self-Serve, Domain-orientation, Data Products ,
Note, Domain orientation is similar to Domain Driven Design (DDD) - both prioritize the business domain, however, DDD is a methodology, whereas Domain orientation is a more general strategy or philosophy.
First, let’s take a quick look at Confluents’ maturity model again.
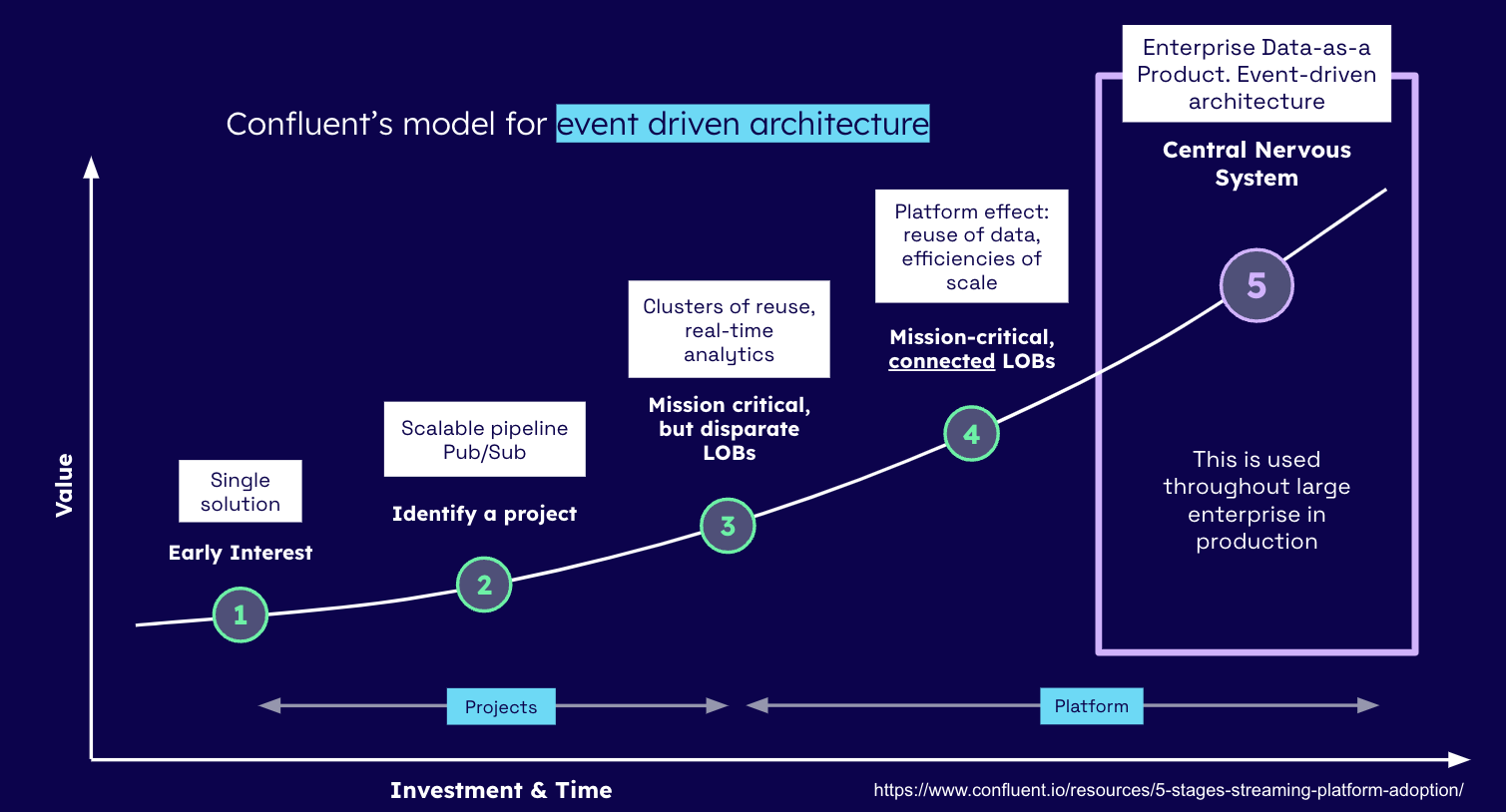
Level 5 isn’t free, it involves a lot of concerted effort and planning. Most of those challenges (and solutions), as we move along the X-Axis, are discussed here. It’s interesting to note, that when talking about Data Mesh and the Central-Nervous System (CNS) it quickly becomes obvious that the two approaches are closely aligned with respect for achieving very similar goals.
Please note that this post is heavily biased towards Apache Kafka. I will be using terms such as ’topics’, ‘partitions’, and ‘schemas’ which, though fairly generic, are applicable to and can be translated into alternative technologies. For example, Kafka Topics == AsyncAPI Channels.
DDD Terminology
Before we dive in too deep - let’s get two heavily used terms out of the way - Bounded Context versus Aggregate.
Both Aggregate and Bounded Context are patterns in Domain-Driven Design (DDD). They both help to manage complexity, but they operate at different levels and have different purposes.
Aggregate: An Aggregate is a cluster of associated objects that we treat as a unit for the purpose of data changes. Each aggregate has a root and a boundary. The root is a single, specific entity contained in the aggregate that’s responsible for enforcing the invariants (business rules) for the whole aggregate. The boundary defines what is inside the aggregate. An important rule of aggregates is that a transaction should not cross aggregate boundaries.
For example, in an e-commerce system, an Order might be an aggregate. It may contain many OrderLineItems, and there might be rules about what kinds of items can be added to the order, the maximum or minimum number of items, etc. The Order is the aggregate root, of enforcing these rules.
Bounded Context: A Bounded Context is a higher-level concept. It defines the context for a model within which the model applies. In other words, it sets the boundaries within which a certain model is valid and makes sense. It encapsulates specific functionality and language interpretation within these boundaries. Each Bounded Context can be mapped to a specific part of the organisation, or a specific business capability.
Consider a generic e-commerce system where you might have different Bounded Contexts for Order Processing, Inventory Management, and User Account Management. Each of these has its own distinct models, and terms within each Bounded Context may have different meanings. For example, the concept of “Customer” in the Order Processing context might be different from the concept of “User” in the User Account Management context.
In short, an Aggregate is a pattern that helps to manage complexity and enforce consistency within your data models, while a Bounded Context helps to manage architectural complexity at a larger scale by separating out distinct areas of the system, each with its own unique language and carefully controlled interactions.
And then…some Data Mesh Terminology
Data Mesh is the latest hype-cycling, show-boating technology - that much like microservices, no one can really agree upon what it is. However, there is consensus that there exist four pillars: Governance, Self-Serve, Domain-orientation, and Data Products. While DDD is a methodology, Data Mesh is more concerned with Data Architecture. Rather than create more noise, Im going to drill straight into the alignment and overlap between DDD and Data Mesh.
Bounded Context from Domain-Driven Design (DDD) and the concept of a Domain in Data Mesh aim to encapsulate specific areas of responsibility, yet they are not identical. Here’s why:
- Bounded Context (DDD): This is an essential part of DDD, which advises developers to define clear boundaries, both in terms of the problem domain and the corresponding solution space. A Bounded Context encapsulates a specific functionality within an application and includes the models, language (Ubiquitous Language), and operations that make sense within that context. It’s primarily used in the design of microservices and the business logic layer.
- Domain in Data Mesh: In a Data Mesh, the concept of a domain extends beyond the bounds of software design and into data ownership and governance. Each domain in a Data Mesh treats data as a product and assumes full lifecycle responsibility for that data, including its quality, privacy, security, discoverability, and usability. These domains often align with business capabilities or organizational structure.
While both concepts aim at organizing complex systems into smaller, more manageable parts, their focus is different. Bounded Context is more about designing and implementing software around business domains, while a domain in Data Mesh is more about treating data associated with a specific business capability as a product to be managed and used. These concepts can complement each other, and together they can provide a comprehensive approach to managing both software and data complexity.
Later on, I will discuss how the two concepts of Domain and Bounded Context must be aligned through vertical slices.
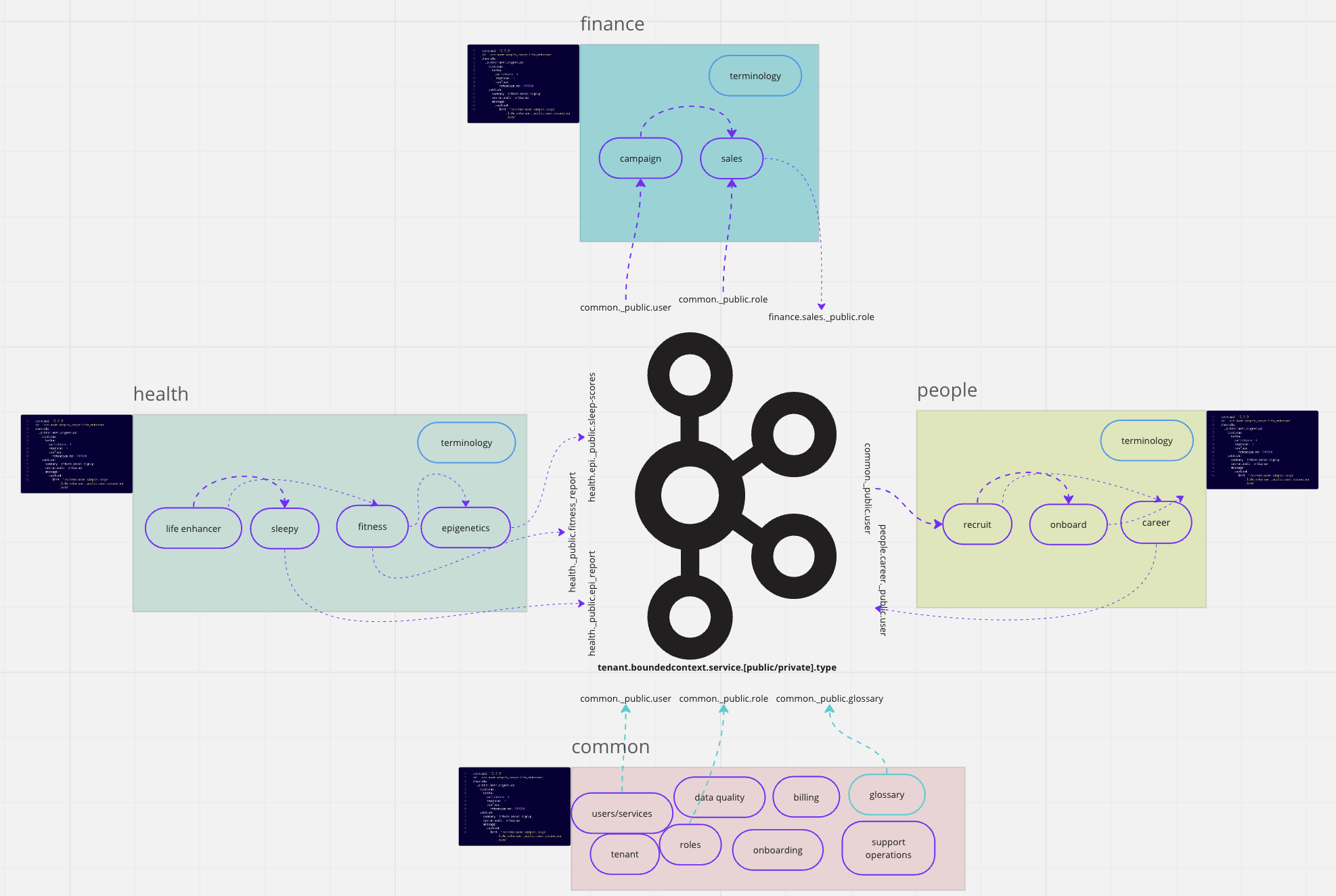
The ACME company 'Bounded Contexts'
In the diagram above, we can see the ‘ACME’ organization’s Domains, represented by colour-coded boxes. The black, text-filled boxes represent Async API specifications that capture the Domains Data product.
Organisational challenges!
Bounded-contexts (BC) are functional units that align with teams. Golden rule - remember that teams and ownership change (ReOrgs happen) but the functionality never does. A key part of any BC is its API - we can call this its Data Product. The AsyncAPI is a good way to define a Bounded Context’s API in an Event -Driven Architecture (EDA), including the API endpoints and the data models. In this sense, we can call the Data part of the stack a Domain (as previously discussed). This makes it the responsibility of the developers/architects to design and own AsyncAPIs using GitOps tools – like SpecMesh OS or JulieOps.
On the other hand, cross-cutting infrastructure concerns such as clusters, servers, AZs, networking, and other server-centric infrastructure naturally fall under the purview of DevOps tooling (Ansible, Terraform etc).
Lastly, we have cross-cutting data concerns. In this context, we start ideating around data quality, data governance, metadata (data catalogue), and policies. As such, a Bounded-Context API will be seamlessly aligned and integrated into this framework.
Examples include:
- Tagging and tracking PII fields
- Governing/Masking access to sensitive fields
- Applying Data Quality rules from a centrally managed team
Enterprise ‘Event-driven’ architecture
Where do events reside? How can we organise them in such a way that there is clear ownership and a scalable structure that functions effectively? These questions rank among my top five during all client engagements, along with concerns about provisioning and related tooling. If we model the functionality of an enterprise, we can identify discrete units that naturally fit into neat, modular segments. This is intended to be the outcome of practices like Domain-Driven Design (DDD), Event Storming, and the like – the ‘Domain (data model) and Bounded Context (business logic)’ might appear as follows:
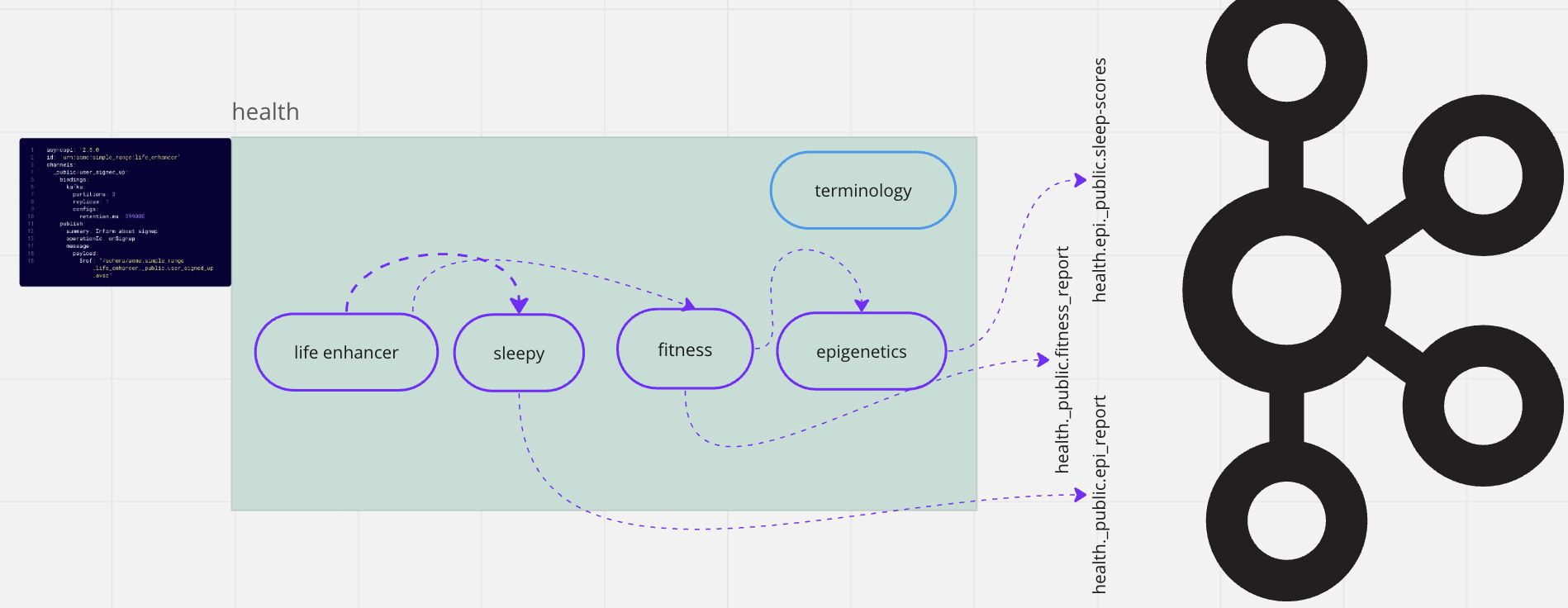
The ACME company 'Health' - 'Domain'
Note: the Domain hierarchy convention being used is as follows:
[domain].[service]
To integrate the event model with the domain & bounded context, the topic naming convention mirrors the same structure. This concept is often referred to as “Events as an API”. Although it’s frequently communicated using the industry-accepted phrase “events as a backbone”, it’s important to note that events will occur at multiple layers, as we will discuss further.
[domain].[service].[access-control].[type]
Access control: private, public, protected
Type: data type
Some topic naming examples:
health.life_enhancer._public.user-scorehealth.fitness._public.user-healthfinance.campaign._public.sale
Enterprise requirements
Up until this point, we have only covered BCs, DDD, and organising things for scale with an EDA. It’s when we start dealing with organisation-wide, shared-use and the day-to-day reality of running the system that we begin to comprehend an expansive set of functionalities. It makes sense to strategise around these fairly early on as they can be difficult to change later.
These functionalities/requirements can be summarised as follows:
- Scaling
- Self-Governance
- Policy Driven
- AsyncAPI spec
- Control Plane
- Chargeback
- Data Catalogues, Data Discovery, Glossary & Meta Data
I’ll cover some of them briefly, but suffice it to say, they rank high on the Confluent Maturity Curve and can be quite expensive to implement. Often, they will be specific to an organization. However, we can technologically align some of them very quickly.
Scaling - It’s all about vertical slices of everything
Consider this topic name: finance.campaign._public.sale
The topic name makes it abundantly clear that owning BC & Domain is ‘finance.’ Consequently, we readily grasp the intended scope (_public) as well as the data being published (Sale). This approach is simple – it can be understood by anyone. It needs to be applied to all layers of data, ops and infrastructure of the Bounded Context. All elements relating to the Domain, including the codebase, should form a vertical slice that can be traced from top to bottom.
Here is a short checklist:
- Service accounts should use principles reflecting the domain owner or aggregate identity, such as ‘acme.finance.campaign.’
- Codebase: packing reflects ‘domain orientation’ modelled down to individual service names - i.e. package finance.campaign.sales, service name: SalesProcessor.
- Repository name reflects bounded context (a collection of related services). I.e. Git:
https://github.com/acme/finance - Build pipeline - tied to the Repository build pipe
- Release process - tied to the Repository build pipe
- Services and topic provisioning - scripts contained in the BC repository will execute EKS, ECS clusters using the BC+service names.
- Support and operations tooling - emit logging events to the correct packaging. Trace events are package similar to the code base - package and service name
When all of these are adhered to we end up with a functional part of the org that everyone can understand. It can support blackbox release processes and more. It makes things simple.
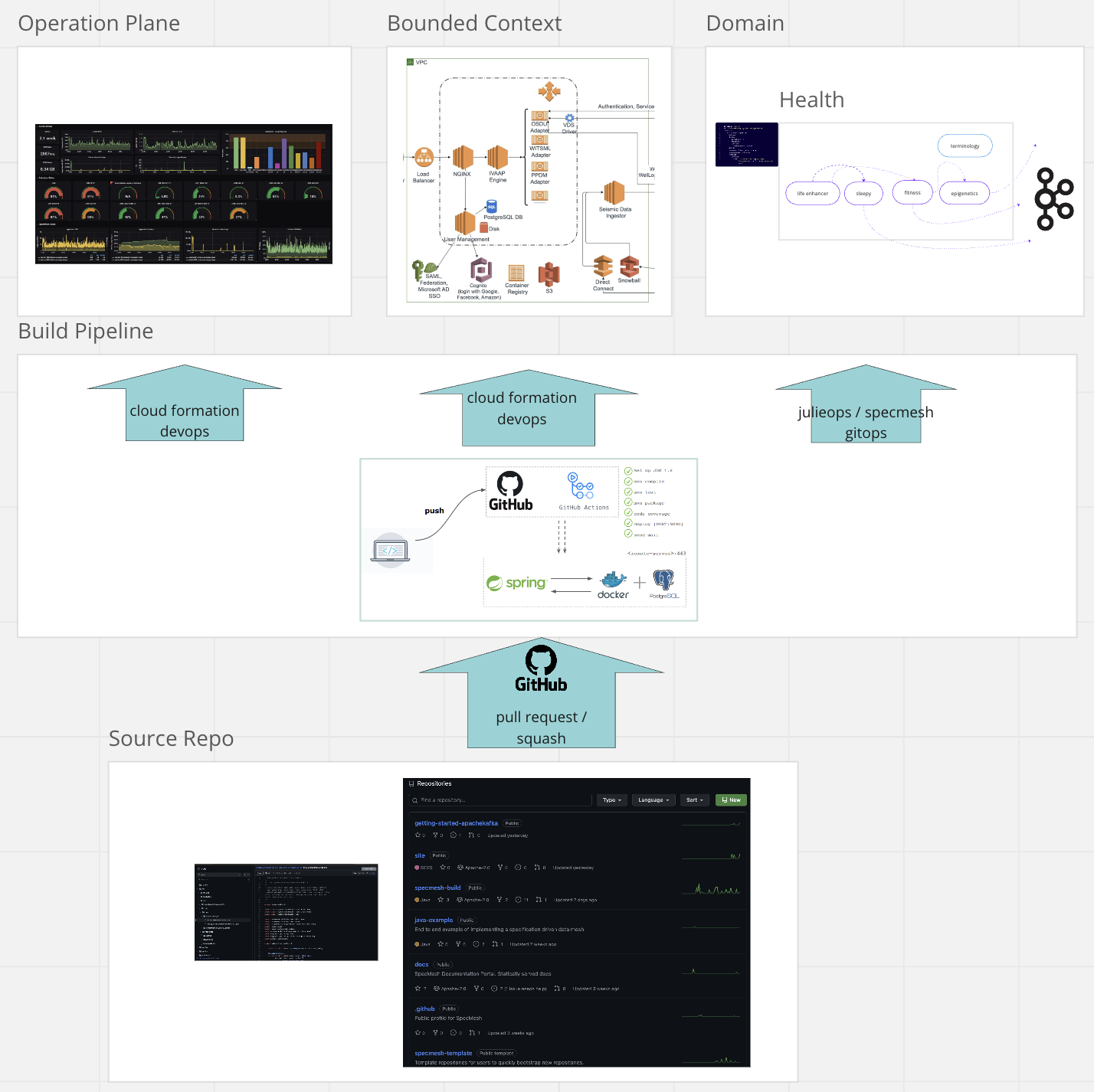
A Domain is a slice that cuts from codebase to runtime and data infra
Some common pitfalls
The concept of Domains & Bounded Contexts needs to be functionally oriented, not organizationally oriented. This simple yet essential statement must be remembered: organizations change, but functionality doesn’t. We are enforcing a data model.
Moreover, given that this is the foundation of our data model, topic naming should never reflect infrastructure. For instance, a name like acme.us-east1.blah.blah.blah is inappropriate. This is because infrastructure and data models are separate concerns. Consequently, such naming conventions imply that data cannot be migrated between regions or environments without necessitating a rewrite or mapping.
One final consideration is that some services within the Bounded Context are likely to share data. A prime example is ’terminology’. Each Bounded Context will have its own set of standardized services, and ’terminology’ is quite common among them. It refers to the set of terms shared in the domain space. For example, in finance, this might include terms like purchase, sale, credit, debit, etc.
Test and release
Bounded-Contexts provide an excellent level of abstraction for Blackbox testing. To achieve Blackbox testing, it is popular to dockerise the Kafka infrastructure, seed/static data (user) and then inject test data, while asserting against edge/output topics of the BC. This can be summarised by:
- Functional Testing/behavioural: Test the functionality of the aggregate by providing inputs and checking the outputs without considering how the output was produced (including negative testing). This is also known as input/output testing. This involves testing a BC method, considering only what the method is supposed to do, not how it accomplishes it.
- Boundary Testing: Test the aggregate with inputs at the extreme ends of input domains and validate the outputs. This could involve providing inputs that are just inside or outside the allowable input range.
Blackbox testing focuses on the Bounded Context’s behaviour, inputs and outputs, not how it internally accomplishes tasks. This approach aligns well with DDD principles, which prioritize domain rules and behaviours over technical details.
Self Governance
Apache Kafka vendors support several types of access control mechanisms (ACLs, RBaC, IAM). The standard version is referred to as Access Control Lists (ACLs). There will typically be many ACLs used to control all kinds of access; they can quickly become unwieldy if not carefully managed. Organizing topics and resources within the aforementioned hierarchy can significantly simplify the process. SpecMesh.io, mitigates the complexity of ACL configuration by leveraging topic naming by introducing keyword placement using _public, _private, and _protected. This simplification approach makes topics readable and means users can easily configure topics (via editing the Spec), understand the sharing approach and implement and access control using a single resource (Git). Ill discuss this more in more detail in the next section.
The ultimate goal should be self-governance, with an aim to prevent bottlenecks within infrastructure teams.
Being Policy and API Driven with the AsyncAPI Spec
The AsyncAPI is an API schema/framework/ecosystem that emphasizes asynchronous communication patterns. It can be used to define a single EDA or a collection can be used to define parts of a large, distributed EDA. The API can be treated as the Domain’s API and Data Product. The last 12 months have seen an explosive interest in its adoption. While many tools exist for code generation and documentation, SpecMesh uses these specs as the source of truth (GitOps style) to provision Kafka resources and control access to them. It enables self-governance for data access, such as _public, _private, and _protected topics, and can also be extended to apply policies.
Note: Access rules apply as follows:
_publicgrants read access to all principles and restricts ‘write’ access to the owning BC._privaterestricts read and write access to the owning BC._protectedenables self-governance where atag: grant-access:some.bounded.contextis used to grant restricted access to other principles, for example,some.bounded.context.
Firstly, let’s examine the types of policies we aim to define. Policies dictate how events are handled, validated, authorized, and processed by various components of the event-driven system. Kafka policies typically relate to access (as mentioned above), retention, discovery, and accessibility.
A classic example is Personally Identifiable Information (PII). In the case of SpecMesh, it’s possible to use the AsyncAPI to build a BC level API/Contract to govern access, and control retention periods (for example, PII should only be stored for 48 hours - SpecMesh can override retention based on metadata), and make topics with PII tags discoverable (via a Data Catalogue). This meta layer can then used to implement data cleansing, masking, and anonymizing specific fields.
Who owns the policy? In this case, the PII policy would be managed in conjunction with the Orgs’ tag glossary and data catalogue - it’s the responsibility of the CDO/Data team. Individual SpecMesh build pipelines access the glossary, searching for tag-centric configuration and topic overrides. For cleansing, centralized tooling (in the control plane) would be utilized to clean, filter, and anonymize fields before they can be accessed. For instance, a rule might allow _protected access, and a control-plane owned/operated cleaning service would ‘rewrite’ the topic with _public access (once the event data has been cleaned). Similarly, data quality rules could be centrally organized and executed by a data quality team - integrated via the control plane - and driven using tags.
Chargeback
One of the challenges faced by any large organization is securing funding for enterprise projects. Typically, this is achieved by implementing an internal chargeback strategy/metrics/system for the consumption and production of data. I have observed countless projects in which various Kafka metrics have been extracted. However, due to the lack of domain orientation, deriving metrics from unstructured resources has proven incredibly difficult. This issue arguably makes it one of the most problematic, yet crucial, aspects of building Enterprise Apache Kafka.
Tools like SpecMesh promote responsible behaviour by ensuring that topics, ACLs, consumer-ids, and other resources map to BCs. Only through this method of requiring guardrails can SpecMesh extract the production and consumption metrics of a data product.
One solution is to use SpecMesh OS storage and consumption commands:
- https://github.com/specmesh/specmesh-build/blob/main/cli/README.md#command-storage-chargeback-metrics
- https://github.com/specmesh/specmesh-build/blob/main/cli/README.md#command-consumption-chargeback-metrics )
Control Plane and Common Data
Until now, we have been operating in the ‘data plane.’ The control plane runs orthogonally to this. I’ve built systems that implement a control plane which performs many functions, such as pausing event processing, draining topics, rebalancing consumers, etc. However, due to the AWS SaaS architecture whitepaper, they also bundle control entities into the same bucket. This specifically relates to entities like Tenants, Roles, Users, Services, Onboarding, Billing, Glossary - essentially, the set of services required before anything else can be built.

The ACME company 'Control Plane' - 'Bounded Context'
If you don’t want to build most of this yourself, then SpecMesh will get you most of the way there. AsyncAPI specification provisioning, observability, and GitOps semantics equally apply to the control plane/common bounded context.
Data Catalogues, Data Discovery, Glossary & Meta Data
At this point, we briefly delve into the DataMesh space. Please examine the four pillars and see what suits you best; there’s no consensus apart on what a Data Mesh is - apart from the idea that it should be humorously renamed to ‘data-mess’. As we have limited writing space left, let’s just focus on Data Catalogues. Most organizations already possess a Data Catalogue, a Data Quality tool, etc. The data catalogue serves as the endpoint where Developers, Data Scientists, and similar professionals can search, discover, and interact with data, tags, and metadata models; it contains the meta model of everything in the organisation. Think of it like an organisation’s Data DNA. This should include AsyncAPI specifications (if you’re using specmesh.io), as well as metadata attached to event schemas (Protobuf and Avro support metadata annotations - i.e. fields identified as PII). Once discovery is enabled, new products and tooling can search and explore the organization’s data ecosystem to identify potential data sources. There’s no shortage of data catalogues out there - each one has its own unique benefits; it’s quite common for DIY catalogues to be built upon anything from GitHub, S3, however, they tend to require more functionality that engineers will initially appreciate.
I can thoroughly recommend subscribing to the Symphony of Search, LinkedIn, newsletter by Ole Olesen-Bagneux.
Finally
I hope you have enjoyed this mini-series. There is always more to discuss, plan, and figure out. In my opinion, the key element is to employ a systematically consistent approach across the board. Understanding the DNA of your company is pivotal for success. It’s important to know whether you should build or buy, understand the reach of an organization-wide strategy, and consider how people and politics might obstruct such decisions, thereby driving an incremental strategy.
Some key takeaways:
- Building for scale and the enterprise requires Domain orientation (Bounded Contexts) to instil clear ownership of resources and to also establish governance and chargeback.
- Agree on a common BC structure/pattern that works for your company based on functionality, not organisation structure.
- Vertically slice from code-repo/services -> build pipeline -> topics/clusters using BC alignment.
- Require black-box testing of BCs.
- Capture BCs using the AsyncAPI spec.
- Support discovery of a Domain’s data products by publishing to a Data Catalogue.
- Aim for specification-driven governance that enforces topic naming conventions and access control.
Finally, if you want to accelerate all of this and get beyond level 5 of the Confluent maturity curve, then look at SpecMesh.io - it will solve 90 percent of the challenges mentioned above (or prevent you from making mistakes that are impossible to fix later). Yes - this sounds like a sales pitch - but there is truly nothing else out there that is Open Source and does all of this.
Finally finally, if you want to have a free 45-minute chat on building an enterprise-level eventing platform - please reach out.
.....
Resources:
- https://specmesh.io/blog/specmeshenterpriseevents-p1/
- https://specmesh.io/
- https://github.com/specmesh/specmesh-build
- https://github.com/specmesh/docs/wiki
- https://docs.aws.amazon.com/whitepapers/latest/saas-architecture-fundamentals/control-plane-vs.-application-plane.html
- https://www.linkedin.com/newsletters/6937422474598883328/
- https://martinfowler.com/articles/data-mesh-principles.html
- https://www.confluent.io/en-gb/blog/event-streaming-benefits-increase-with-greater-maturity
- https://www.infoq.com/news/2019/06/bounded-context-eric-evans/
- https://www.asyncapi.com/
- https://conference.asyncapi.com/
..