SpecMesh OS - Journey to the event-driven enterprise with Apache Kafka - Part 1 of 2, June 2023

– Neil Avery (Ex-Confluent)
Reviewed by Andy Coates (Ex-Confluent), Stanislav Kozlovski (Confluent)
Building the ‘central nervous system’ is one of those phrases that presents a simple concept, but in reality, it turns into an enormous, complex, and challenging task that is generally done incorrectly. This blog post attempts to cover the fundamentals, decisions, thinking, and wider considerations that need to be assembled in a logical way. By leveraging these learnings and relying on tools that simplify processes and adhere to best practices, most pitfalls can be avoided. I’ve divided the post into two parts. The first part deals with events and conditions for events in the enterprise, and the second part focuses on the area where the ‘rubber meets the road’. It covers many of the org level considerations and challenges that need to be overcome in order to build something that is is truely transformative. From Domain orientation, slicing the domain into functional data models, repos and runtimes, to data catalogues and enabling self governance. Ideally, this mini-series should be much longer and filled with more elaborate examples, but I’m trying to provide as much detail and value as possible - in the shortest possible space! My hope is that this information will empower you to embark on your own journey to build an event-driven enterprise with Apache Kafka.
This is Confluent’s maturity model - take a careful look at the X-axis (Investment and Time). The recommendations in this post will significantly reduce the usual investment and time required.
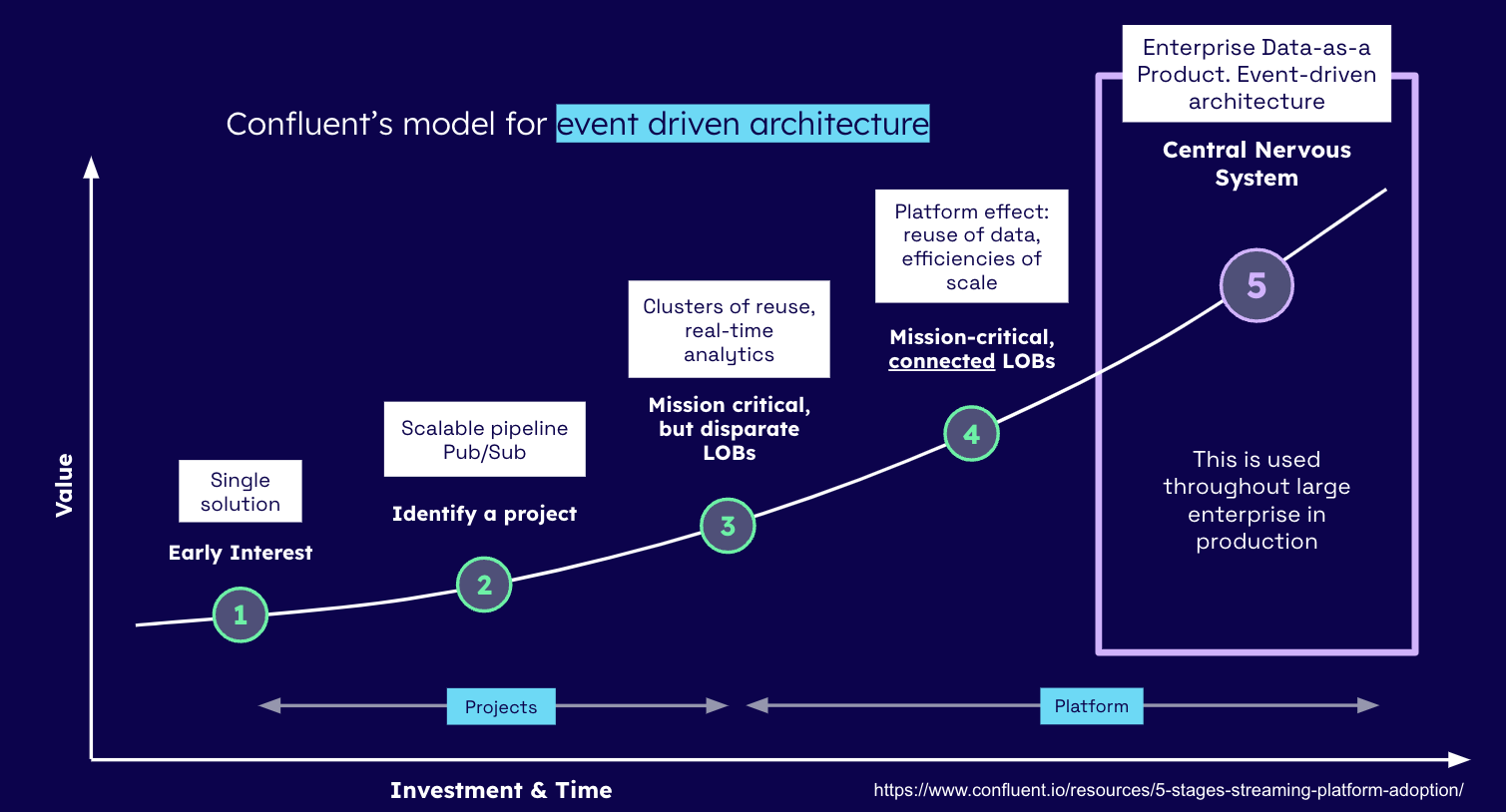
.
Part 1: Unleashing Potential - Essential Event Considerations for Apache Kafka in the Enterprise
Building a small, isolated, event-driven application is relatively simple. However, as the saying goes, it’s not until the application is in production that you create legacy – and legacy implies evolution, responsibility, support, and many other considerations. Scaling this application, implementing access control, ensuring observability, and providing support then become essential considerations in the application’s design. Before you know it, the project has grown far beyond the simple idea we first started with. In an ironic twist, ‘Hello World’ has become ‘HELLO WORLD!’. Suddenly, we are faced with an explosion of responsibility.
This post breaks down the various considerations that need to be made, establishing fundamentals and also provides guardrails and guidelines for building large-scale Event-Driven Architecture, (EDA) for the enterprise. Unfortunately, Apache Kafka doesn’t give you this for free; it an open streaming platform that is unopinionated and with seemingly disparate, yet related resources. Topics can use any naming structure, while referencing schemas that use any subject, and a myriad of sometimes confusing access control restriction strategies - this leads to complete freedom to choose anything that makes sense at the time. It often leads to conflicting, competing or evolving strategies on any one of them… and also many many fundamental issues that are expensive to unravel. Consequentially, this was the motivation for building, SpecMesh.io O/S. SpecMesh makes Apache Kafka suitable for the enterprise. That doesn’t mean that some mistakes won’t be made along the way, but that’s the point of this post. Rather, it is to instill knowledge, so that educated decisions can be made.
Modelling events at scale involves understanding complex elements such as domain orientation, bounded contexts, aggregates, common data and data types, org functional hierarchies, roles, and evolution (data and functional), amongst other challenging aspects. To make the ‘big decisions’ early on, we must build a solid basis for understanding these factors. Early, less educated, decisions can be costly to undo, often to the point that the organization will have to simply ‘make do’ and live with the outcomes.
Let’s talk about Events in the enterprise
What is an event? (this has been covered a lot!) - see my blog post from 2018
The original blog series: Journey to Event Driven – Part 1: Why Event-First Programming Changes Everything
This blog series was a widely adopted education source for organisations trying to navigate their event-driven journey; however, a lot has changed since then. Part one is great for the conceptualization of why we need to think about being ’event-first’. If you’ve not read it, I’d recommend reading it before proceeding.
How many different types of events are there?
Events in an Event-Driven Architecture (EDA) can be classified into several types depending on their nature, source, and purpose. Here are a few common types of events:
- Domain Events: These are events that represent something of importance happening within the business domain. For instance, in an e-commerce system, examples of domain events could be “OrderPlaced”, “OrderCreated”, “PaymentProcessed”, or “ShipmentDispatched”. These events may cause a state change to multiple domain entities.
- System Events: These are events that are triggered by the system itself, often relating to the health, performance, or status of the system or its components. Examples could be “CPU”, “Disk Utilization” (i.e. infrastructure metrics) or higher level events like “ServiceStarted”, “ServiceStopped”, “SystemOverloaded”, or “DiskSpaceLow”. (Lifecycle Events)
- Integration Events: These events are used to communicate between different Bounded Contexts or services in a system. They allow loose coupling between services, as one service can react to state changes in another without directly knowing about it. They are typically used in microservices architectures.
- Lifecycle Events: These events are related to the lifecycle of a process or a task. They include events like “ProcessStarted”, “ProcessCompleted”, “TaskCreated”, “TaskUpdated”, and “TaskDeleted”.
- Time-based or Schedule Events: These events occur at specific times or intervals. They might be used for scheduling tasks or triggering certain actions at specific times. An example could be a “DailyInventoryUpdate” event that’s triggered every night at midnight.
- Data Events: These events relate to changes in data. They can be a result of Create, Read, Update (UPSERT), and Delete (CRUD) operations on data storage. Likewise, UPSERTs.
It’s likely that you will read the list above and think, we have other types of events as well (delta’s, observable, facts, commands, rules etc). The problem is that the concept of events is just that - conceptual. It can be anything, the data model, like Kafka is unopinionated. The only pure event is a Change Data Capture (CDC) event - it doesn’t carry any information other than the state object CDC, as an event pattern it can be used for metrics, domain events etc - because it’s only carrying state information.
CQRS (Command Query Responsibility Segregation) is a high-level, event-centric architectural pattern. Despite showing its age, we often see ‘Commands’ (which some people like to masquerade as events). In Kafka, CQRS is readily used so frequently that it is no longer a thing. Its common to use a connector to project events to a Read or Query layer (such as Elastic, etc). I will discuss Commands further down.
We should aim to build Event-Driven Architectures (EDAs) using Choreography, where producers and consumers are oblivious to each other. They are decoupled, and the only shared understanding is the event structure as dictated by its schema. This means we should focus on CDC as the primary eventing model.
What is a CDC event and what is so good about them?
In a Change Data Capture (CDC) system, events are typically triggered by Create, Update, and Delete (sometimes also Read) operations in a database. In the EDA world, we can adopt the same concept, and use them as the basis of all eventing models. We model them as follows:
- Delete: ‘null’ for delete - for example. key: order-id-100, value: null
- Create: receive an event where the previous state does not exist.
- Update: receive an event where an existing state does exist. Sometimes, this can be in the form of partial updates, however, it only works with event sourcing where the originating state is built using a backup source (snapshotted events).
In the ‘OrderPlaced’ example, the CDC approach ‘Placed’ becomes obsolete, thereby eliminating the need for an attribute that enhances data coupling knowledge (stateful awareness) between the producer and consumer. That is to say, an Order event is sent. When an Order did not exist, it is created, where the order did exist, it was updated - effectively performing an UPSERT. When the Order is placed, an inventory service could check stock levels, a price comparison service could check competitor prices, and a logistics service could estimate the price of shipping. I prefer this approach because it promotes Choreography over Orchestration. The producer and multiple distinct consumers remain oblivious of each other; the event acts as the API and should, therefore, be pure (only contain state information). This design allows the system to evolve. There might be different versions of the same consumer, they may transition among each other, and all these changes are invisible to the producer. This factor is a primary consideration when building systems that can operate 24x7 and support evolving business functionality. Please note that this point is separate from event evolution.
Ideally, we model all events using CDC. It makes schema management (data evolution), and data-flow (functional) evolution simpler. Ideally, the need for ‘Placed,’ ‘Deleted,’ and other enumerated states coalesce into the CDC model. That being said, there will be times when an observable (derived) event is needed (i.e. OrderPlaced, OrderCreated, ItemPurchased). Ideally, these events won’t travel across the backbone - more on this later.
What about Commands & Events?
In an Event-Driven Architecture (EDA), the term “Command” and “Event” are distinct, each with its specific meaning and usage.
- Command (intention): A Command represents a request for an action or change to be made in the system. Commands are imperative and tell the system to do something. They are typically directed at a specific target, often a domain object or a service, which is capable of executing the command. A command usually expects some side effect to occur as a result of its execution. Examples of commands could be “CreateOrder”, “UpdateUserDetails”, or “DeleteProduct”. They are often used in the context of the Command Query Responsibility Segregation (CQRS) pattern.
- Event (fact): An event, on the other hand, represents something that has already happened in the system, typically a state change. Events are descriptive and are named in the past tense, such as “OrderCreated”, “UserDetailsUpdated”, or “ProductDeleted”. Events do not expect a response and are not targeted at a specific receiver. Instead, any part of the system interested in the event can subscribe to it and react accordingly.
The primary issue with ‘Commands’ is that they embody an API, a Contract, thus necessitating shared knowledge of this contract between the producer and consumer. This goes against the principle of Choreography, thereby transitioning into orchestration.
Yes, ‘Commands’ can be utilized (and will sometimes be necessary), but they should be restricted to a single bounded context’s code repository. This includes the set of related services that are operated, maintained, and upgraded in unison. If Commands ever cross a Bounded Context, the operational burden and complexity could potentially become insurmountable.
Another issue with Commands is their incompatibility with Event sourcing. Hence, if a system state is migrated to a different environment (PROD → UAT), a workflow dependency on the Command event and the event-sourced state, constructed/built as a result of processing those Commands, needs to be migrated first (or all Commands drained). The operational complexity and the additional burden on tooling this situation create is apparent.
It’s crucial to keep these definitions clear in your architecture to maintain a predictable and understandable system behaviour. Each of them - Commands and Events - plays a unique role in the choreography and orchestration of the operations in a system.
Evolutionary thinking about events
Event data models will always change, which means building a ‘change strategy’ from the outset is essential. However, there is no clear consensus on how to handle this - so I will give you my opinion.
Changes to the data model can have wide-reaching effects because they can impact all the services that consume the affected events. Especially where Choreography (decoupled knowledge between producer/consumer) - is the paradigm of EDA.
Here are several strategies to protect an EDA when the data model changes:
- Schema Evolution: Use a method of serializing data that supports schema evolution, such as Apache Avro, Protocol Buffers or JSON schemas. This allows you to add new fields to your data model in a backward and forward-compatible way.
- Versioning: Introduce versioning for your events. If the data model changes significantly, create a new version of the event. Services can then gradually migrate to the new event version, while older services can still consume the old version. With Apache Kafka this can be archived by versioning topics - but note - the operational burden can require significant planning and tooling (offset management etc)
- Consumer-Driven Contracts: Use consumer-driven contracts, which are tests that define the expectations of event consumers. These tests can be run whenever the data model changes to ensure that consumers won’t be broken by the changes.
- Event Transformation: Implement an event transformation layer that can transform the new events into the format expected by the consumers. This could be particularly helpful when dealing with legacy systems that are hard to change.
- Notification and Coordination: When you must make breaking, un-evolvable, changes that require a new topic; communicate with the teams responsible for all affected services. Olt topics need to be deprecated. Give them time to update their services to handle the new data model.
Remember that data model changes should ideally remain technical issues that naturally resolve themselves, when they become organisational issues there will be many knock-on effects and unforeseen consequences - this should be avoided where possible. For example, a core-data object, ‘User’ has contention about how it should be modelled, one department required European-only requirements (as it currently works), while another requires a global model - (expanding upon the existing). Changing the European-only model will affect legacy systems - there is a cost associated with this work. Who pays for it?
Notwithstanding, where Versioned topics are required - one way of implementing them is for the authoring service to be updated to use v2 of the model and use “event transformation” to downscale this to the old model and produce into the v1 topic (where possible). This simplifies decommissioning the v1 topic, it’s much cleaner and therefore more likely to happen. Versioned topics require a mechanism for notification and orchestration. The v1 topic should be marked as deprecated (e.g. in the data catalogue). Users of the v1 topic should be notified of the v2 topic and given a timeframe for migration. So, while Versioning is possible, it has a significantly higher total cost of ownership.
The ideal solution is to use Schema Evolution (#1) - which leads to a few other decisions. Which format - Avro, Protobuf or JSON?

Avro, Protobuf and JSON
I can find arguments in favour of any one of these over the other. Having decided on a format, the evolution style needs to be selected (depending on the SR being used) - we have the following considerations.
- Which registry? Choose from Confluent SR, Red Panda, RedHat (APICurio), AWS Glue SR, and Memphis.dev SR (if you are using their platform)
- Schema enforcement on WRITE, READ, BROKER side.
- Client-side code LoE and TCO (Serialisation and DeSerialisers - AKA SerDe) - should be available OOTB. For example, is Kafka Streams, Flink or another streaming runtime being used and how is it encoding schemas, handling security (encryption) and configuring Kafka client properties; the solution could be to provide an org-specific library and/or boilerplate template, and/or code-generation.
Each registry has its own set of nuances. For example, with Confluent SR, the provided SerDe libraries encode the schema-id into the first four bytes of the payload. This ‘id’ - is a monotonically increasing number unique to that particular SR cluster. Migrating to another cluster requires a Schema Registry exporter. I’m not a fan of this approach. Of course, it is possible to run your own SR based on GitRepo/Versioning semantics while rolling your own SerDes.
My default mode of operation involves using the Confluent SR, Avro, and Java client SerDes. However, it’s important to note that each organisation will have its unique requirements and preferences. Despite the diversity in languages, libraries, and strategies, every Kafka client must function efficiently, embodying a ‘good actor’ role in terms of its reliability, failure modes (i.e. dead letter queues), and responsiveness. What strategies do you employ to achieve this goal?
Modelling domain entities in an EDA?
Modelling domain entities in an event-driven architecture (EDA) requires a slightly different approach compared to traditional service-oriented or monolithic architectures. In an EDA, the focus is more on the changes in the state of the entities (or the events) rather than the entities themselves. Domain entities might be generated from an event-storming/DDD workshop that extracts Bounded Contexts, and models the interaction between them and within them. I will cover this in more detail in part 2.
First, here is a sneak peak of an enterprise system for a fictitious company called ‘ACME’. There are four Bounded Contexts (BC). The red BC contains cross cutting/shared entities. Each BC is defined using an AsyncAPI spec.
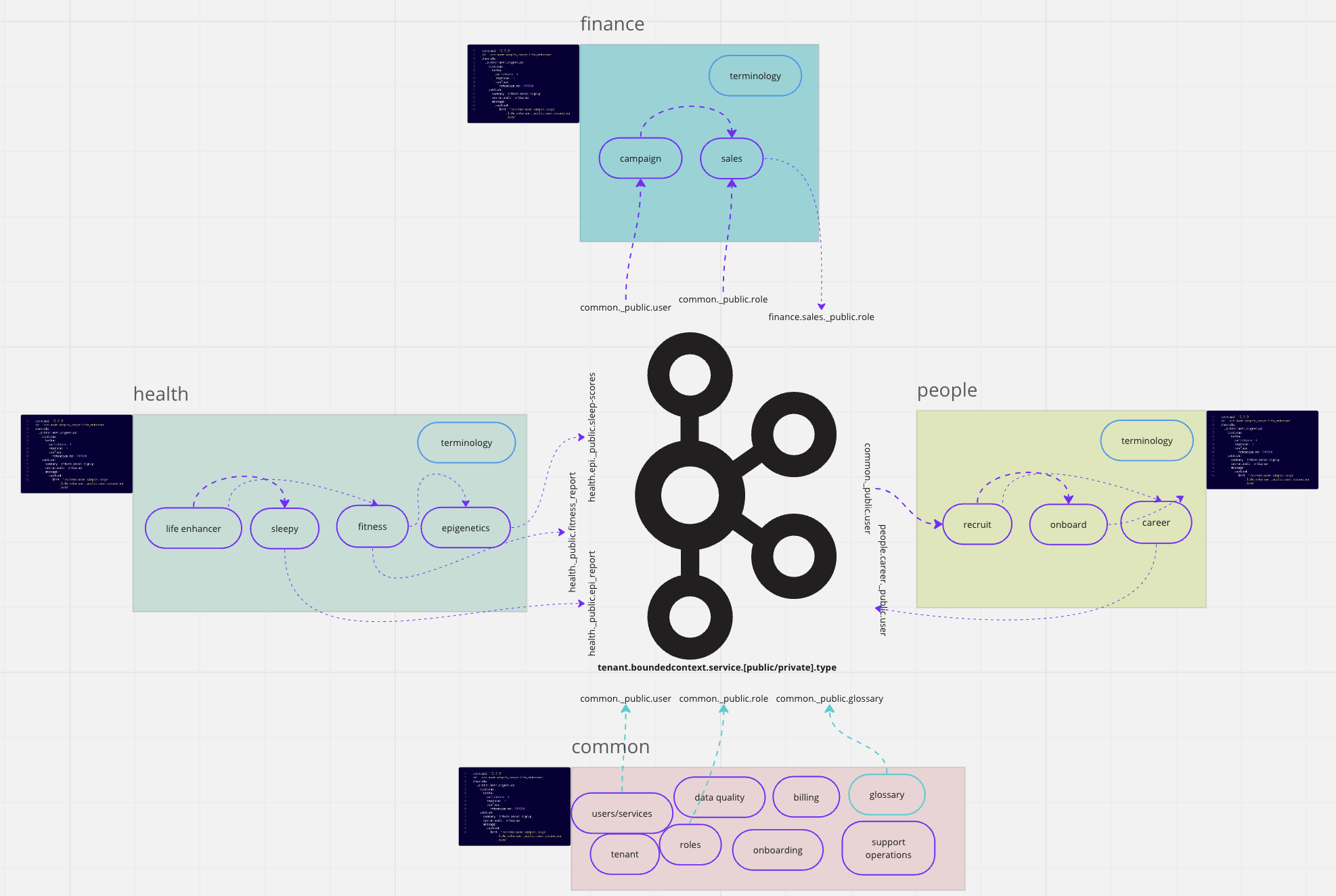
The ACME company 'Bounded Contexts'
Here are some guidelines for modelling domain entities in an EDA:
- Identify Key Entities: Start by identifying the key entities or objects in your domain. These are usually nouns that are involved in your system’s business processes, such as “User”, “Order”, “Invoice”, “Product”, etc.
- Identify Value Events: For each entity, identify the significant state changes that occur during its lifecycle. These state changes become the events in your EDA. For example, an Order entity might have events such as “OrderCreated”, “OrderUpdated”, “OrderPaid”, “OrderShipped”, etc. These should be modelled using CDC.
- Identify Common entities: These entities are part of the common-data model that is shared across the organisation - it will typically include entities such as User, Address, Payment etc.
- Design Event Schema: Each event should have a well-defined schema. This includes the type of the event, a timestamp, the version of the event schema, and the payload (data associated with the event). The payload typically includes the unique identifier for the entity and any other data related to the event.
- Model Entity State as a Series of Events: In an EDA, the state of an entity at any given time is typically modelled as the series of events that have occurred to that entity. This concept is known as Event Sourcing. For example, the state of an Order might be derived from the sequence of “OrderCreated”, “OrderFullfilled”, “OrderPaid”, etc. events. Again - model these using CDC.
- Design Event Handlers: You’ll also need to design components in your system that listen for these events and handle them appropriately. These handlers might update a database, trigger other events, interact with external systems, or perform other actions.
Remember, in any EDA it’s essential to think in terms of events and how these events affect your domain entities, as opposed to focusing purely on the entities themselves. It about the data-flow, the interaction and evolution.
Finally..
In an EDA, any decision you make will have ripple effects that can impact the entire system. It’s essential to think ahead and make sure you’re making choices that align with your strategic goals and provide room for growth and adaptation. A well-designed system can handle changes with no disruption, but this requires careful thought, planning, and commitment from the outset.
As we navigate this complex journey towards building a large-scale Event-Driven Architecture, remember that the goal is not perfection, but rather continuous improvement. We can always learn from our mistakes and use that knowledge to make better decisions in the future. Let’s embrace the complexity, learn from each other, and continue to build better, more resilient systems.
There are a few key takeaways from our discussion:
- It’s crucial to identify domain entities and events using EventStorming or Domain-Driven Design (DDD). This will give a clear overview of the architecture and reveal opportunities for simplification and decoupling.
- Events can be categorized in various ways; they could be used as a ‘key’, as common or shared entities like ‘User’, or within a Bounded Context (either as private or public).
- We should strive for Change Data Capture (CDC) events wherever possible, as they provide a pure and flexible framework for event-driven systems.
- It’s important to restrict Commands within a Bounded Context, thus preventing shared knowledge and unnecessary dependencies across different parts of the system.
- Always ensure everything is schematized to guarantee compatibility, evolution, and manageability of the data model.
These best practices provide a robust foundation for an effective enterprise-ready, Event-Driven Architecture.
Building an event-driven enterprise with Apache Kafka is an exciting and challenging endeavor, but one that promises significant rewards in terms of flexibility, scalability, and resilience. As we continue this journey together, I look forward to hearing about your experiences and learning from them. Stay tuned for the second part of this series, where we will dive deeper into the world of Apache Kafka and its role in the enterprise. Until then, happy building!
.
Resources:
- https://specmesh.io/blog/specmeshenterpriseevents-p2/
- https://specmesh.io/
- https://www.infoq.com/news/2019/06/bounded-context-eric-evans/
- https://www.asyncapi.com/
- https://conference.asyncapi.com/
- https://github.com/specmesh/specmesh-build
- https://github.com/specmesh/docs/wiki
..