
AWS Data Zone vs SpecMesh OS for Kafka (fight!), October 2023
– Neil Avery (Ex-Confluent) AWS Datazone vs SpecMesh OS for Kafka …
Read more ⟶Specification driven data mesh for the enterprise
For organisations to successfully adopt data mesh, setting up and maintaining infrastructure needs to be easy. We believe the best way to achieve this is to leverage the learnings from building a ‘central nervous system‘, commonly used in modern data-streaming ecosystems. This approach formalises and automates the manual parts of building a data mesh.
SpecMesh combines Kafka best practice, blue prints, domain driven design concepts, data modelling, GitOps and chargeback. But rather than talk about it, we decided to build it!
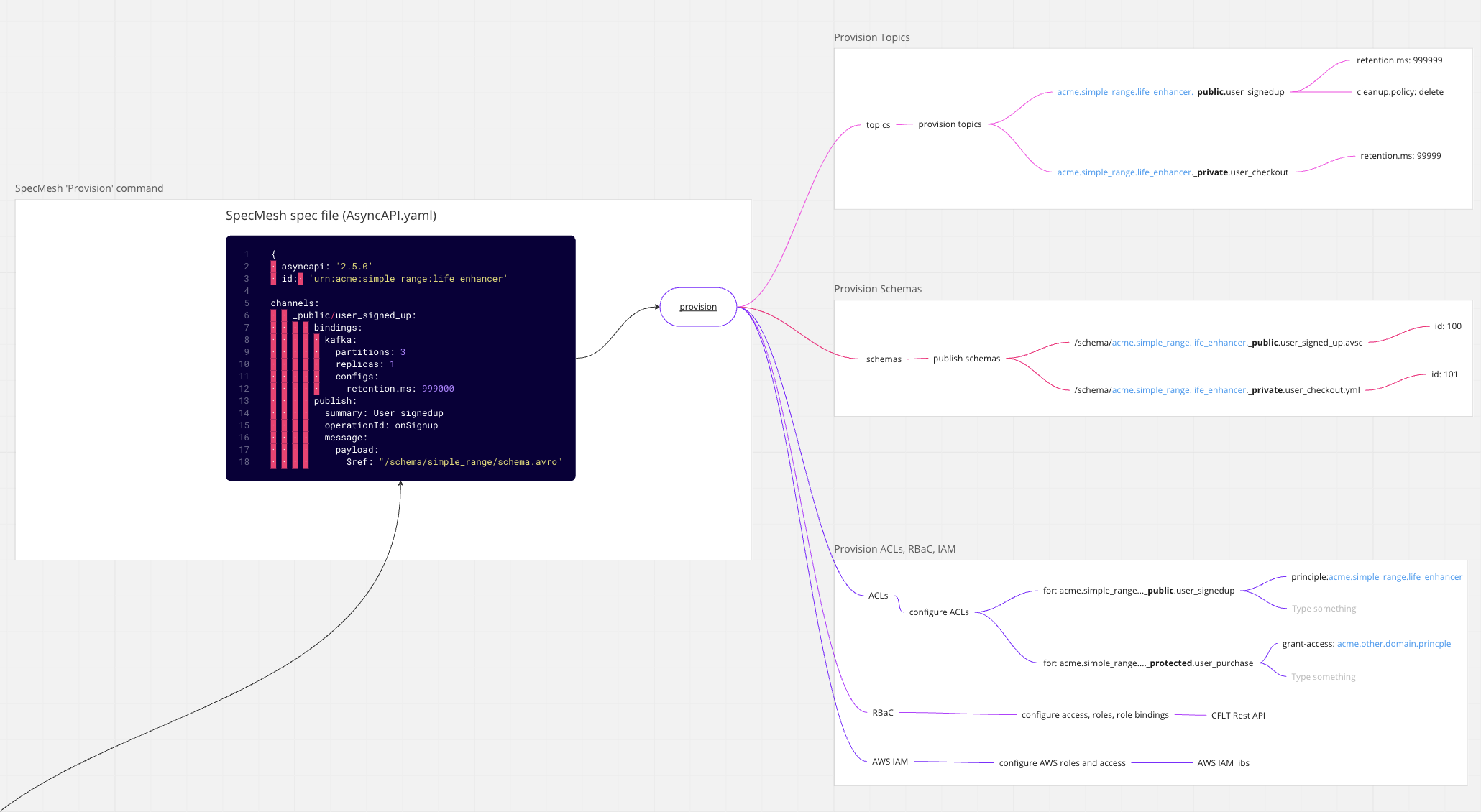
AsyncAPI specs model the API for an event driven applications set of topics. SpecMesh will dryRun, validate and provision Kafka resources
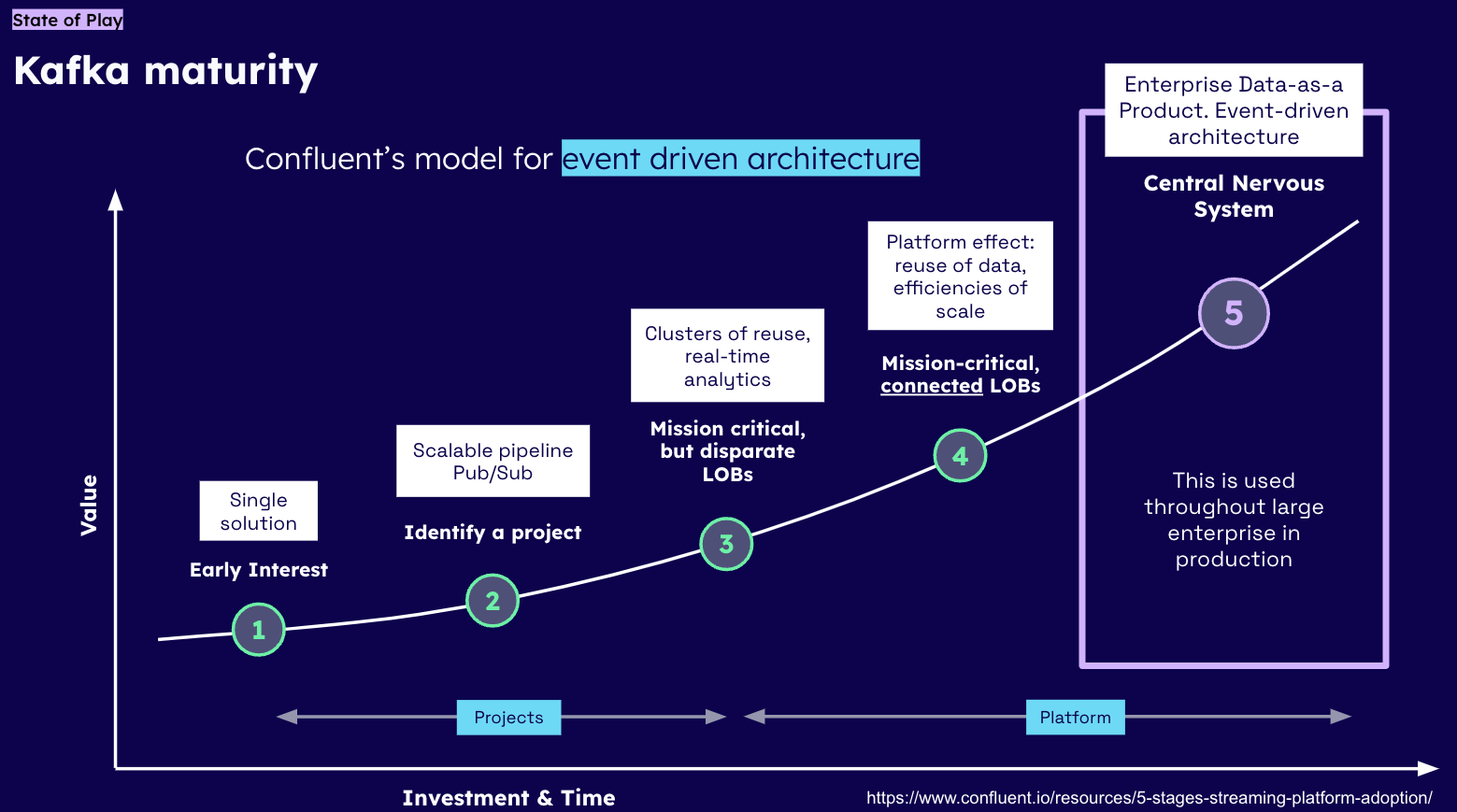
It takes a team many years to reach Level 5, the "Central Nervous System" stage. SpecMesh accelerates this journey
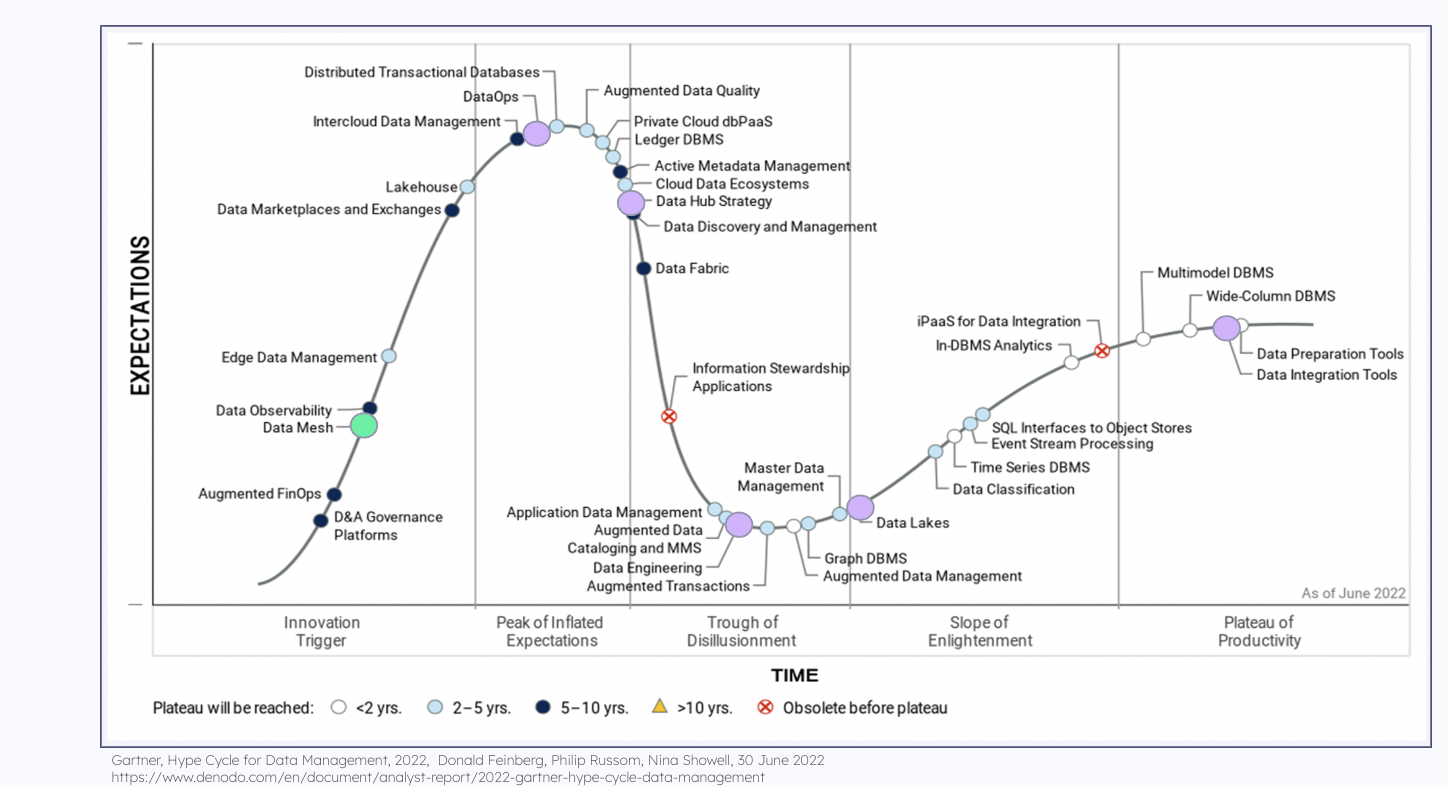
Data Mesh aligns closely with the functionality required for constructing a Central Nervous System. It enhances discovery by incorporating data cataloging and introducing federated governance
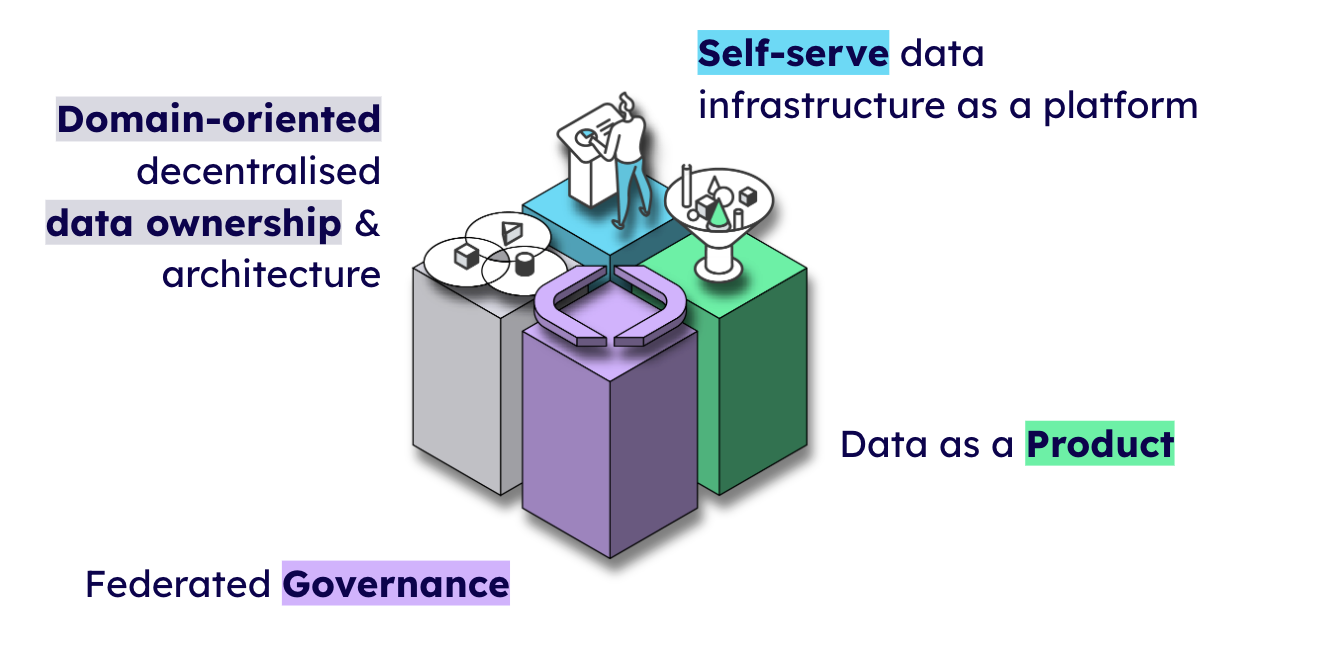
Data Mesh is a confusing space. The 4 Pillars are the only thing that is truly agreed upon. SpecMesh addresses them all
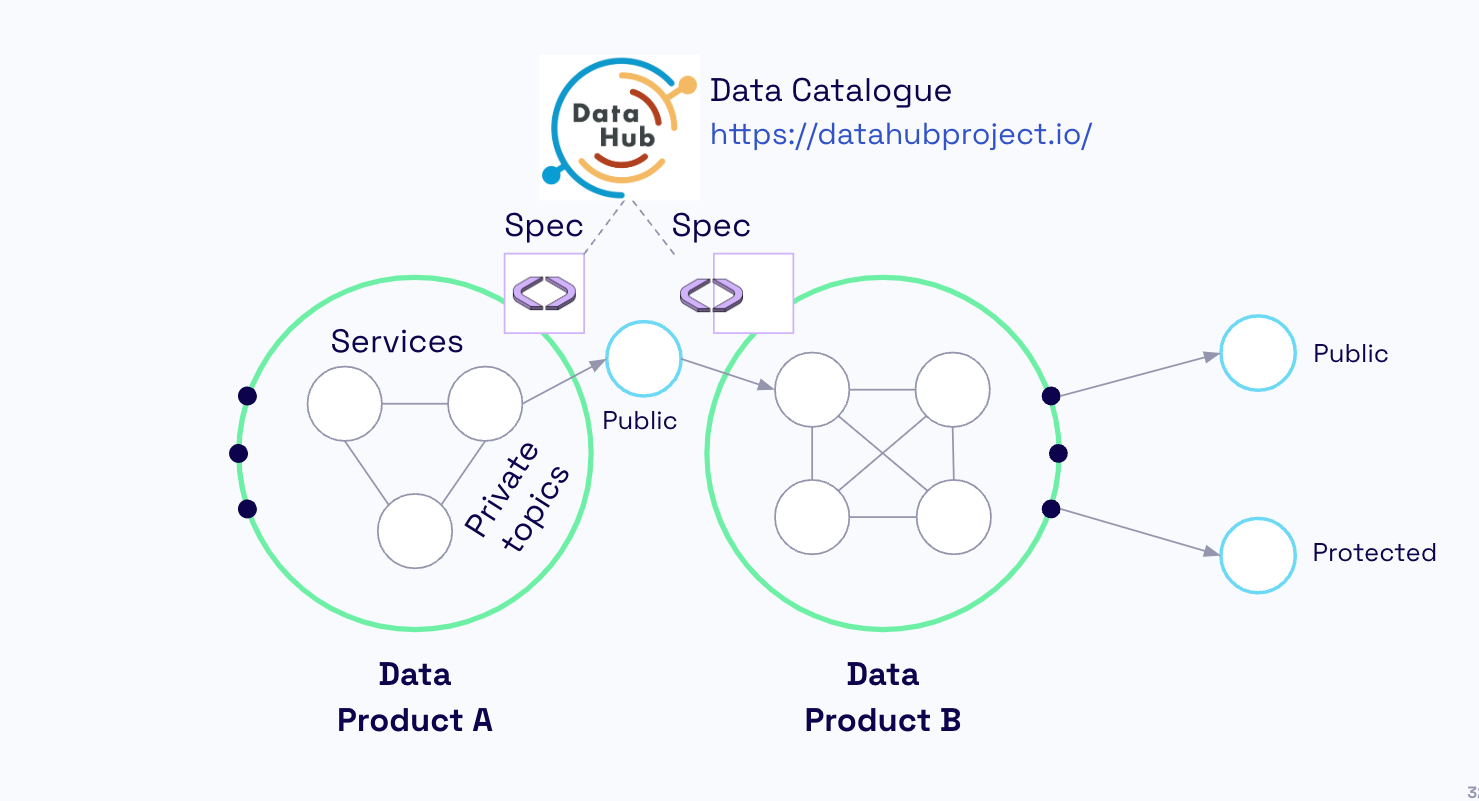
Once each Spec (Data Product) is provisioned, the meta data (spec + schemas) is published to a data catalogue to enable discovery
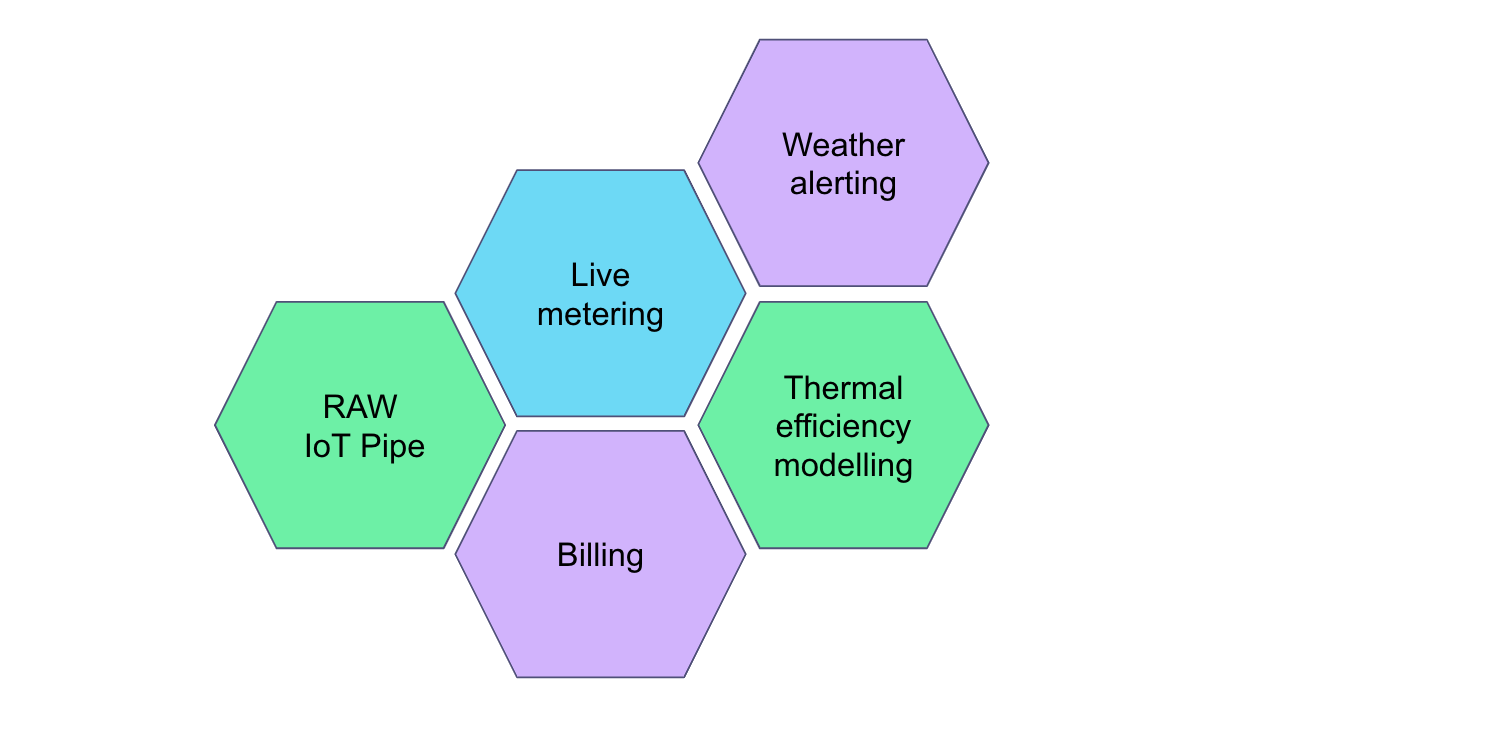
As the organisation grows more and more Specs (Data Products) are deployed where services emit events over domain structured '_public' and/or '_protected' topics
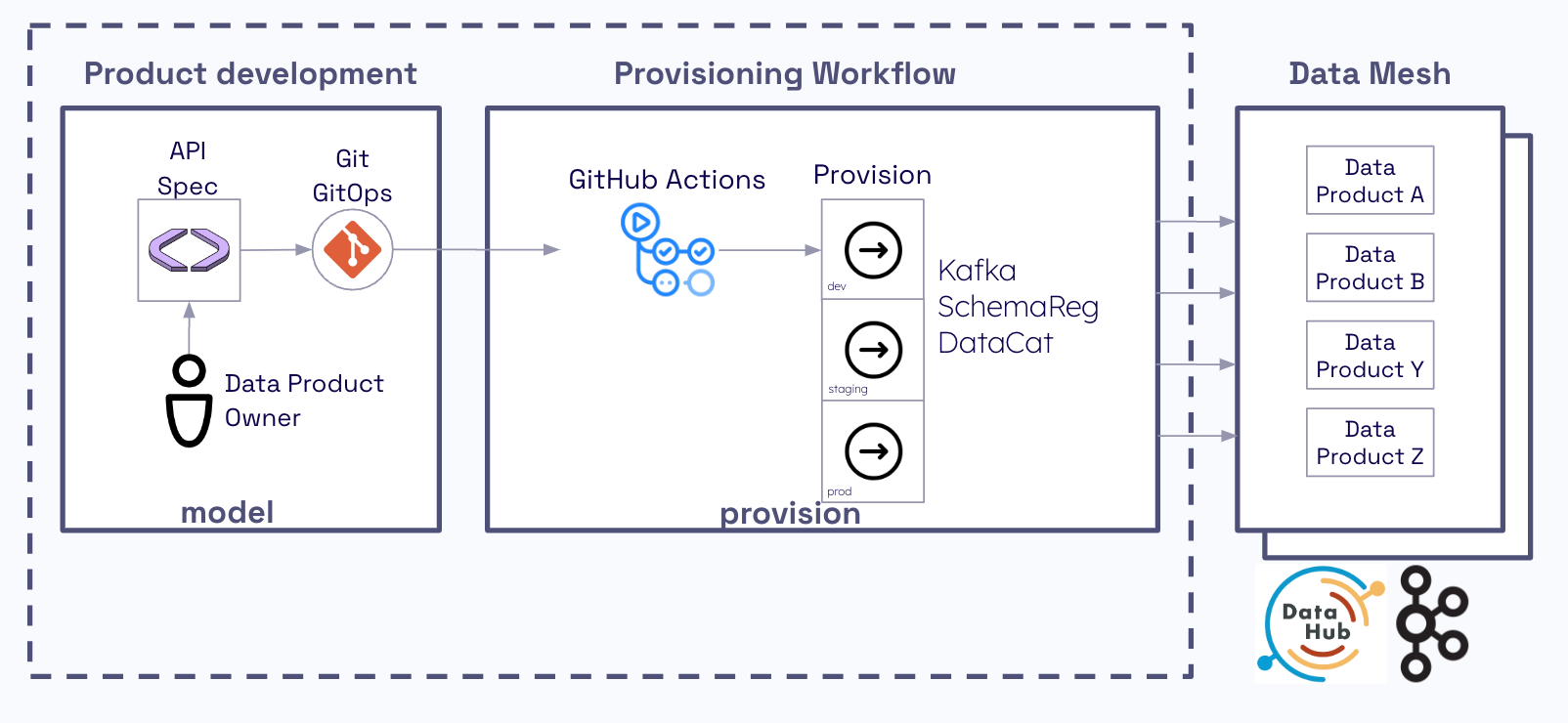
Each team owns and manages their own AsyncAPI spec. The spec is provisioned using GitHub Actions. The build workflow provisions each environment as the spec is promoted
A developer toolkit for streaming data mesh built on Apache Kafka
Build your Kafka applications using the industry standard AsyncAPI spec.
Read more ⟶Specs capture 'Aggregates' that represent units of business functionality. This hierarchy incorporates a structure that allows for clear and concise ownership and governance rules.
Read more ⟶SpecMesh will model topics, schemas, and permissions as a unified configuration, rather than using the disparate configurations employed by other tools.
Read more ⟶By modeling a collection of topics under a single app that uses a common hierarchy, SpecMesh is able to report on storage and consumption metrics that can be used to build chargeback systems.
Read more ⟶Topic names can use a '_protected' label, this allows a tag to be incorporated where the application owner can grant permissions to other domain-ids (principals)
Read more ⟶SpecMesh will support a dataflow-centric visualization of all related specifications (apps), their relationships, as well as producers and consumers (coming soon).
Read more ⟶With a decades of insights and expertise, we’re reimagining streaming data so that you can focus on your business.
– Neil Avery (Ex-Confluent) AWS Datazone vs SpecMesh OS for Kafka …
Read more ⟶– Neil Avery (Ex-Confluent) Why are we here There are a couple of …
Read more ⟶
– Neil Avery (Ex-Confluent) Working with MSK A walkthrough showing …
Read more ⟶'I think what you guys are doing is really good. We've used JulieOps at Smart, but found it quite clunky, with neither Infra or Dev wanting to take ownership of it. SpecMesh's focus on data modelling is spot on.' Architect @SmartPensions - London
‘We spent 2 years trying to build this and what your guys have built is better’ Architect @Tier-1 Investment bank - London
‘3 years ago we started evolving to this, instead i wish we could use SpecMesh now’ Manager @One of Europe's largest retailers
‘SpecMesh is much better thought out than our current solution which took our team over 2 years to develop...and we still can't solve chargeback’ Architect @Tier-1 Investment bank - London
‘Why doesn't Kafka have this already? It just makes sense...’ Attendee @Kafka Meetup London
‘We are planning to ditch our broken solution and use this approach,’ Manager @Nordic Shipping firm - Big Data London
‘Self governance and chargeback and modelling using an AsyncApi Spec just makes sense’ Attendee @BigDataLondon
‘We will now use terraform just for server infra, and make SpecMesh GitOps developer led. It just makes sense’ Founder @EdTech startup
‘We currently use JulieOps but need features that it looks like your guys will develop (and it doesn't have)’ Tier-1 Investment bank - London
It was created by Neil Avery (Ex-Confluent), Sion Smith (OSO DevOps CTO) and Andy Coates (Ex-Confluent)
Yes absolutely, either start a chat via an Issue, Enhancement or PR and we can go from there
It's first-come, first-served; however, ultimately, it's the three of us and whoever else is showing interest.
It uses the Kafka Admin Client (like all Kafka admin tools - Ansible, Terraform and Kafka scripts). This means it works with Open Source Apache Kafka, AWS MSK, Red Panda and Confluent Cloud and Confluent Platform
It's unlikely - there is too much value to build up the stack
It will focus on LinkedIn's DataHub
Liquidlabs and OSO DevOps
Create an Issue in GitHub and we will be notified - https://github.com/specmesh/specmesh-build/issues